


Опубликовано пользователем admin
Reddit — социальный новостной сайт на английском языке, на котором зарегистрированные пользователи могут размещать ссылки на какую-либо понравившуюся информацию в Сети. Одна из самых популярных социальных сетей в мире, где пользователи публикуют новости: видео, спорт (НБА, НХЛ), игры (КС, КС ГО, WOW, Hitman, Pokemon, Warframe, Дота, Дота 2, Warhammer, Fallout, Battlefield, Mortal Kombat, Tap Titans, GTA, Red Dead Redemption, Call of Duty, Heroes of the Storm, Legends), стримы, анекдоты, трейлеры фильмов, anime и другое.
Это статья, посвященная алгоритмам, которые формируют рейтинг в разделе Hacker News. Здесь мы рассмотрим, как работает рейтинг рассказов и комментариев на сайте Reddit на примере данных 2018 года.
В первой части сфокусируемся на том, как формируется рейтинг рассказов на Reddit. Во второй части мы сосредоточимся на рейтинге комментариев, который формируется не так, как рейтинг рассказов (за исключением Hacker News). Алгоритм, формирующий рейтинг на сайте Reddit, довольно интересен.
Разбор кода рейтинга рассказов
Reddit является источником с открытым кодом. Он имплементирован на Python, где и размещается его код. Алгоритмы сортировки Reddit используют имплементацию Pyrex, то есть язык, используемый для написания расширений Python C. Reddit применяет Python из соображений скорости. Алгоритм рассказов по умолчанию, называемый «горячий рейтинг», имплементирован следующим образом:
В математической форме горячий алгоритм выглядит вот так:

Влияние времени публикации
О соотношении рейтинга рассказов и времени их публикации скажем:
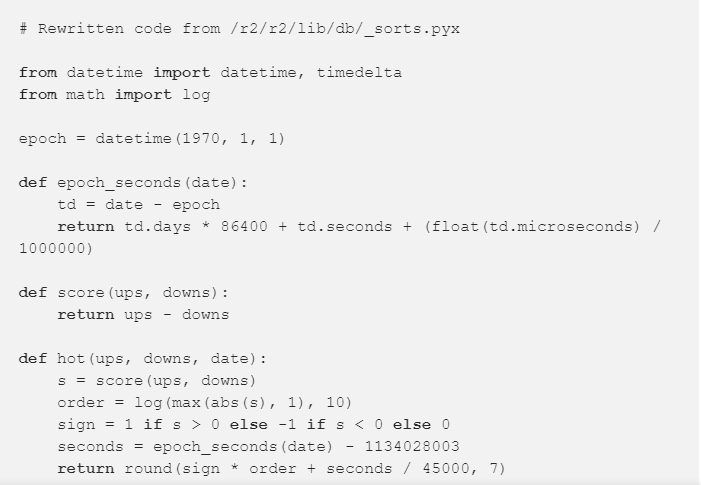
- Время публикации имеет большое влияние на рейтинг: новые истории будут стоять в рейтинге выше, чем старые.
- По прошествии времени рейтинг публикаций не будет снижаться, но новые истории будут иметь более высокий рейтинг, чем старые.
- Данный подход отличается от используемого в разделе Hacker News’, где рейтинг снижается по прошествии времени
Ниже можно увидеть визуализацию рейтинга истории с одинаковым количеством отрицательных оценок, но разным временем публикации:
Логарифмическая шкала
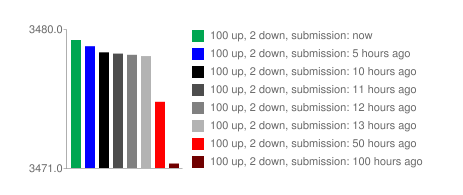
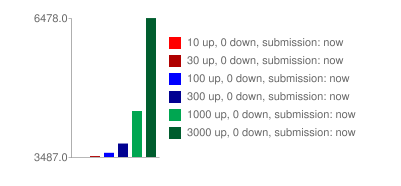
Горячий рейтинг Reddit использует логарифмическую функцию для того, чтобы придать первым оценкам больше веса, чем последующим. Это предполагает:
- Первые 10 оценок имеют такой же вес, как следующие 100, которые, в свою очередь, весят столько же, сколько следующие 1000, и т.д.
Ниже приведена визуализация:

Без использования логарифмической шкалы рейтинг будет выглядеть так:
Влияние голосов против
На Reddit есть отрицательные оценки. Как вы уже могли увидеть в коде, рейтинг рассказа определяется так:
Что это значит – можно увидеть в визуализации:
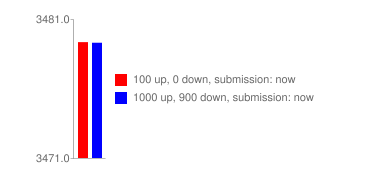
Это оказывает большое влияние на рассказы, которые получают много положительных и отрицательных оценок, так как их рейтинг будет ниже, чем у историй, которые получают только лайки. Этим объясняется тот факт, что милые животные (и другой не дискуссионный контент) имеют такой высокий рейтинг J
Выводы касательно рейтинга историй на Reddit
- Время публикации является очень важным параметром. Как правило, рейтинг новых рассказов будет выше, чем у более ранних.
- Первые десять положительных голосов имеют такой же вес, как следующие 100. Например, рассказ, имеющий 10 оценок, будет занимать то де место в рейтинге, что и рассказ с 50 оценками.
- Рейтинг дискуссионных рассказов с одинаковым количеством положительных и отрицательных оценок будет ниже, чем рейтинг рассказов, которые главным образом имеют положительные оценки.
Как работает рейтинг комментариев на Reddit
В двух словах, как это происходит:
- Использование горячего алгоритма в комментариях – не самое умное решение, так как он отдает значительное преимущество ранее опубликованным комментариям.
- Правильнее давать самый высокий рейтинг самым лучшим комментариям, вне зависимости от времени их публикации.
- Математическое решение для этого было называется «оценочный интервал Вильсона». Оценочный интервал Вильсона может быть превращен в «доверительную сортировку».
- Доверительная сортировка относится к подсчету голосов как к статистической выборке гипотетически полного голосования всеми – как в опросах общественного мнения.
- «Как не сортировать по усредненному рейтингу» дает подробный очерк формирования доверительного рейтинга, определенно рекомендуется к прочтению!
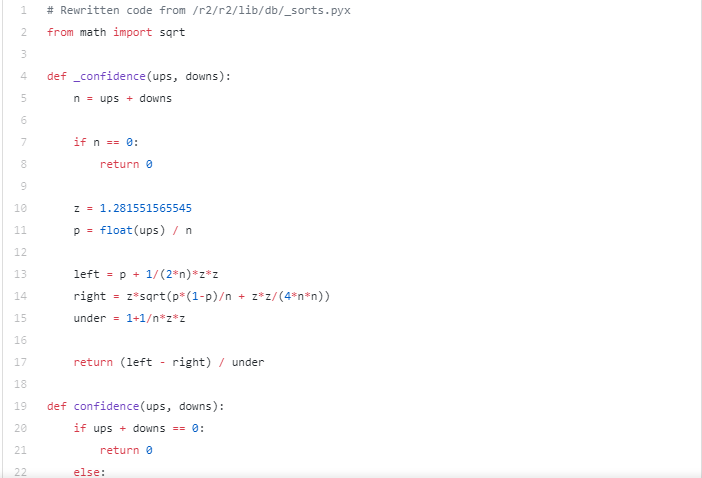
Разбор кода в рейтинге комментариев
Алгоритм доверительной сортировки имплементирован в _sorts.pyx. Я переписал их Pyrex имплементацию на чистом Python (обратите внимание на то, что я также убрал их оптимизацию кэширования):
Доверительная сортировка использует оценочный интервал Вильсона. В математической записи это выглядит так:
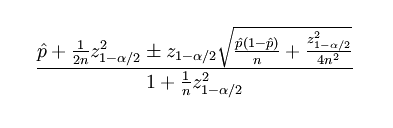
Обозначение параметров в приведенной выше формуле:
- p – наблюдаемая доля положительных оценок;
- n – общее количество оценок;
- zα/2 – это (1-α/2) квинтиля нормального распределения.
Вышесказанное можно подытожить следующим образом:
- Доверительная сортировка относится к подсчету голосов как к статистической выборке гипотетически полного голосования всеми.
- Доверительная сортировка дает комментарию предварительный рейтинг, имея 85% вероятности того, что он его получит.
- Чем больше голосов, тем сильнее оценка с 85% вероятности приближается к реальной.
- Интервал Вильсона хорошо подходит для небольшого количества случаев и/или для крайних границ вероятности.
Вот пример того, как формируется рейтинг комментариев при доверительной сортировке:
Если комментарий получил 1 положительную и 0 отрицательных оценок, его рейтинг будет на 100% положительным, но, так как о нем нет достаточно сведений, система опустит его ближе ко низу рейтинга. Если же комментарий имеет 10 положительных и 1 отрицательный голос, система будет иметь достаточно доверия для того, чтобы поместить его над чем-то с 40 положительными и 20 отрицательными оценками – предполагая, что со временем он тоже получит 40 положительных голосов, можно почти точно сказать, что он будет иметь меньше 20 отрицательных оценок. И лучшее в этом то, что, если данное предположение оказалось неверным (так происходит в 15% случаев), система быстро получит больше данных, так как комментарий с небольшим количеством данных оказался близко к вершине рейтинга.
Влияние времени публикации: его нет!
Одним из преимуществ доверительной сортировки является то, что время публикации не имеет никакого значения (в отличие от горячей сортировки в алгоритме рейтинга Hacker News). Комментарии получают свой рейтинг в зависимости от уровня доверия и отбора данных – чем больше оценок получил комментарий, тем точнее будет его рейтинг.
Визуализация
Давайте визуализируем доверительную сортировку и увидим как она формирует рейтинг комментариев. Мы можем использовать пример Рэндела:
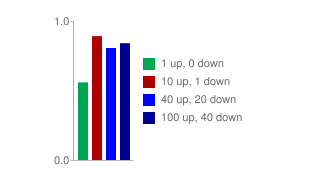
Как видите, доверительная сортировка учитывает не общее количество оценок, полученных комментарием, но его соотношение с количеством положительных оценок и объемом выборки!
Применение помимо рейтинга
Как заметил Эван Миллер, оценочный интервал Вильсона может применяться не только для формирования рейтинга. Миллер приводит 3 примера применения:
- Обнаружение спама/злоупотребления: сколько людей, увидевших этот пост, пометят его как спам?
- Создание списка лучшего (“best of”): сколько людей, увидевших этот пост, пометят его как “best of”?
- Создание списка того, что чаще всего пересылают на почту (“Most emailed”): сколько людей, увидевших этот пост, нажмут на “Email”?
Для применения интервала Вильсона потребуются две вещи:
- общее количество оценок/выборки
- положительное значение оценок/выборки
Беря во внимание то, насколько действенным и простым является интервал Вильсона, можно только удивляться тому, что сегодня большинство сайтов используют наивные способы формирования рейтинга контента. К их числу относятся такие компании-миллиардеры, как Amazon.com, которая определяет усредненный рейтинг через соотношение положительных голосов с общим количеством оценок.
Мы удивлены тем, что многие известные сайты не используют интервал Вильсона. При этом они используют не слишком действенные способы формирования райтинга контента.
Выводы
Я надеюсь, этот материал оказался полезным. Если у Вас есть какие-нибудь вопросы или замечания, оставляйте комментарии.
И, как всегда, приятного хакерства!
Источник: reddit-marketing.pro
